
✨ Codeit Boost 아티클 세미나 2
(2024.11.20)

🚀 세미나 발표 주제
: KNN(K-최근접 이웃) - 와인 등급 예측 모델 생성
📌 와인 데이터 불러오기
📝 코드
📌 Head() 함수 호출
: 데이터 형태 일부 살펴보기
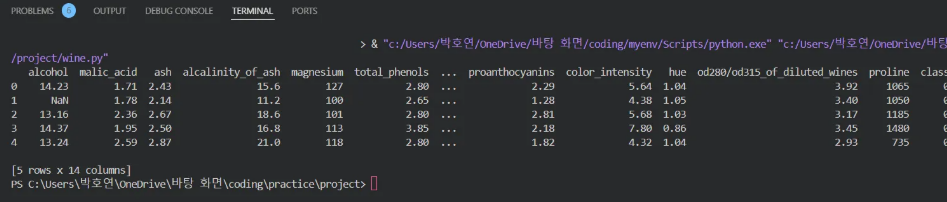
변수는 총 13개입니다.
가장 우측의 class - 목표변수 1개
나머지 12개 변수(alchol, malic_acid 등) - 독립변수 12개
📌 Data.info() - 변수 특징 출력하기
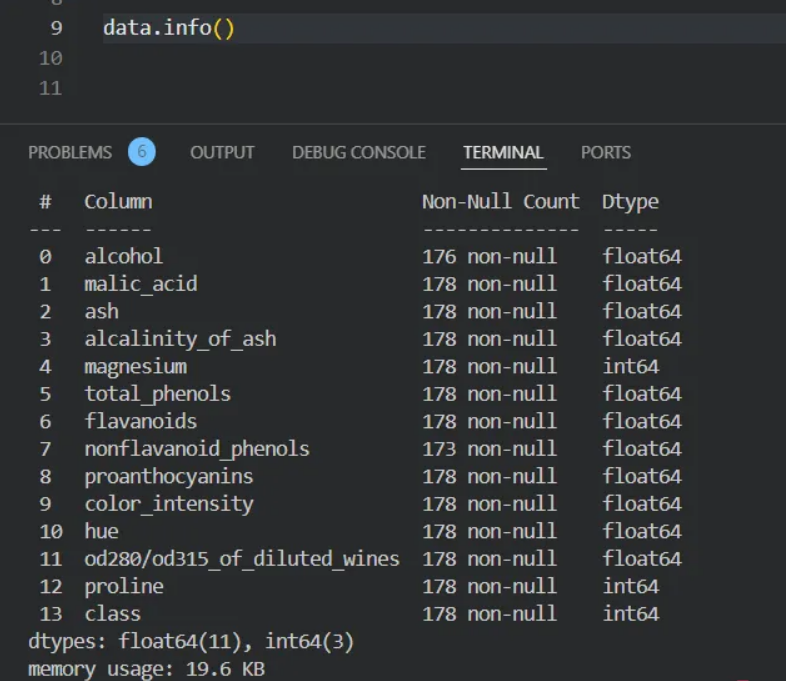
✅ alcohol: 전체 데이터가 178개가 있어야 하는데 176개이므로 결측치가 2개
✅ nonflavanoid_phenols: 전체 데이터가 178개 있어야 하는데 173이므로 결측치가 5개
→ 파이썬에서는 이러한 결측치를 Null 값으로 표현합니다.
📌 위 데이터값이 KNN에서 문제가 되는 이유

✅ 변수마다 값의 범위가 다르기 때문입니다.
✅ malic_acid의 최솟값은 약 0.74이고 최댓값은 5.8인데, proline은 최솟값이 278이며 최댓값이 1680입니다. 즉 스케일이 다르다는 것을 의미하는 것이죠.
→ 따라서 스케일링(scaling, 독립변수의 범위를 동일한 수준으로 맞추는 작업) 필요하다는 결론을 내릴 수 있습니다!
📌 종속 변수 분석하기
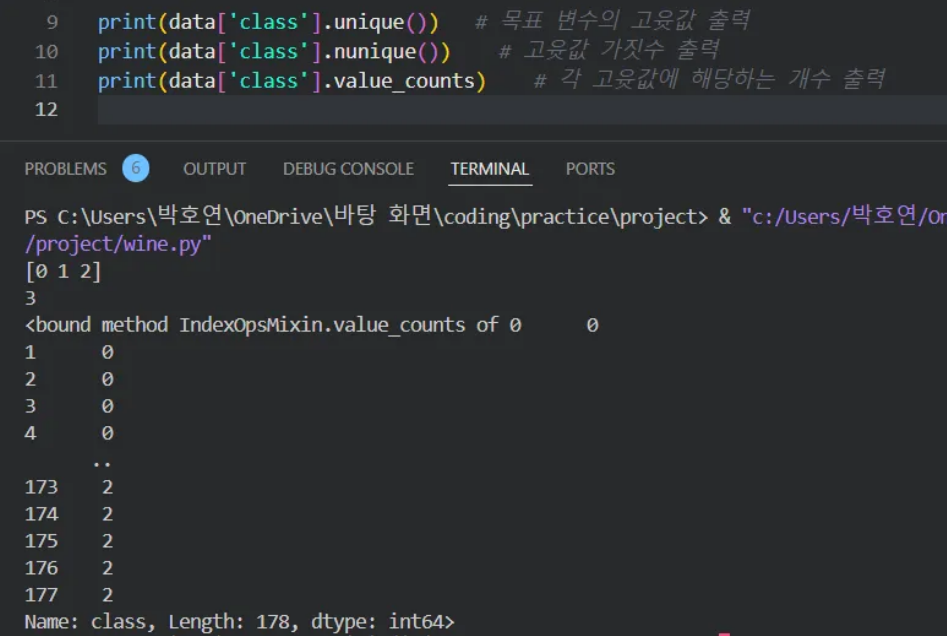
✅ data에서 class 변수를 인덱싱하여 unique() 함수 사용
→ 어떤 값들로 구성된 변수인지 확인 가능합니다.
✅ class에는 0, 1, 2라는 고윳값 3가지가 있습니다.
→ 즉 와인을 세 등급으로 나눈다는 것을 의미합니다.
📌 종속 변수 분석하기
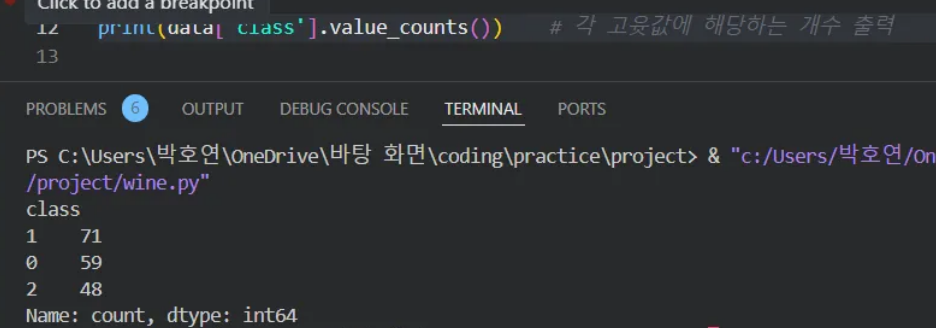
✅ class 1: 71개 / class 0: 59개 / class 2: 48개
📌 데이터 전처리 - 결측치 처리하기
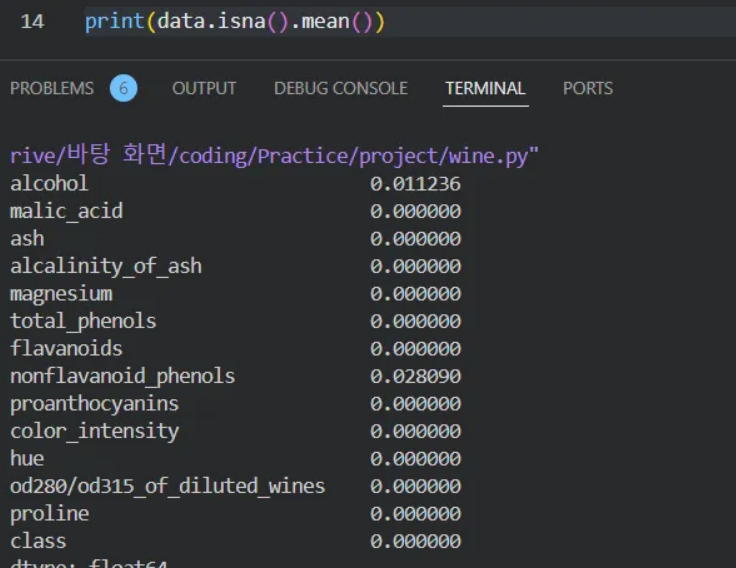
✅ dalchol과 nonflavanoid_phenols 컬럼은 0이 아닌 값이 나왔습니다.
→ Data.info()로 결측치를 살폈듯이, 이 값은 해당 컬럼이 몇 퍼센트나 결측치가 존재하는지를 보여줍니다.
📌 dropna( ) : 결측치가 있는 행 전체를 제거하기
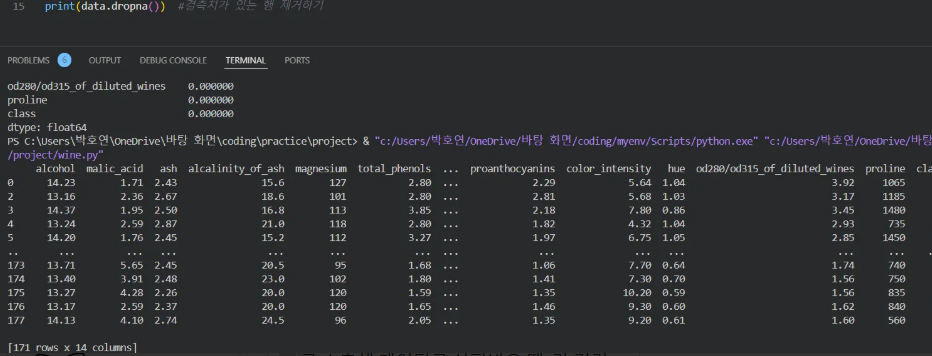
✅ 현재 데이터에서 결측치가 7개 있기 때문에 7줄을 지웁니다.
→ 해당 7줄을 지우면 178줄에서 total 171 줄
📌 스케일링
앞서 describe()를 호출해 데이터를 살펴봤을 때, 각 컬럼들마다 값들의 범위가 다양했습니다.
KNN은 거리 기반의 알고리즘이기 때문에, 이러한 스케일 문제가 안 좋은 결과를 초래할 수 있어서 알고리즘이 왜곡된 예측을 할 수 있다는 문제점이 존재합니다.
이러한 문제를 해결하기 위해 인위적으로 각 컬럼이 비슷한 범위를 가지도록 만드는 작업을 스케일링이라 합니다.</div>
📝 코드
📝 모델링 & 평가
✅ 데이터를 독립변수와 종속변수로 분리한 후, 80:20 비율로 훈련셋과 테스트셋으로 나누고, 최소-최대 스케일링을 적용했습니다.
그런 다음 KNN 모델을 학습시키고, 테스트셋에 대한 정확도를 계산합니다.
최종적으로 accuracy_score를 통해 모델 성능을 평가하여 약 88%의 정확도를 얻었습니다.
📌 정리
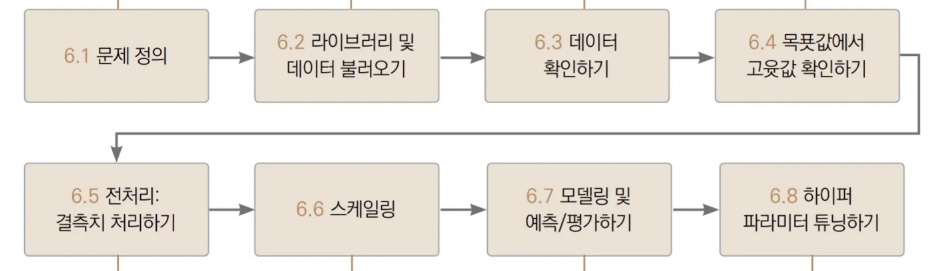
📌 Conclusion
✅ 와인에 대한 정보를 이용하여 와인의 등급을 예측하는 모델을 만들어봤습니다.
✅ 데이터의 결측치와 통계적인 정보를 살펴본 후, KNN에서는 변수의 스케일이 중요하게 작용하기 때문에, 데이터셋에서의 변수의 스케일들을 살펴봤습니다.
✅ 이 데이터값들을 전처리하고 결측치를 처리하는 과정을 통하여 KNN 알고리즘을 이용하여 와인을 3개의 등급으로 분류하는 모델을 만들었습니다